NeurIPS 2017 Summary and Highlights
I was very fortunate to go to the conference on Neural Information Processing Systems (NeurIPS) this year, one of the biggest gathering of AI researchers (indeed, this year’s tickets were sold out in only a few weeks). Conferences like NeurIPS provide great opportunities to learn about recent research (particularly given the sheer amount of research that is released on websites like https://arxiv.org/ every day), as well as tremendous opportunities to discuss techniques and problems with some of the leading experts.
 Registration queue on Sunday afternoon (the day before the official conference start)!
Registration queue on Sunday afternoon (the day before the official conference start)!
 Poster session — roughly 230 posters on each Monday, Tuesday and Wednesday evenings.
Poster session — roughly 230 posters on each Monday, Tuesday and Wednesday evenings.
My head is absolutely packed with new ideas, and have come away with lots of methods I want to try and papers to read. Given the sheer amount of research published at this year NeurIPS, it was impossible to get around every section of the conference. I hope to summarise the conference below, and some of my personal highlights.
Some of the key topics from the conference include: deep learning, GANs, unsupervised learning, model interpretability, meta-learning, deep reinforcement learning, probabilistic and Bayesian learning.
Tutorials
Although I hadn’t registered to attend any of them, it was great that some of them were live-streamed over the NeurIPS facebook page. The Deep Learning: Practice and Trends tutorial provided a useful overview of deep learning concepts and techniques. It also informed on recent trends in deep learning research and applications:
- Autoregressive Models: a time series model that uses observations from previous time steps as input to a regression equation to predict the value at the next time step. Overview of the types used and the applications (e.g. DeepMind’s WaveNet for synthesising speech).
- Domain Alignment/Unsupervised Alignment: learning to translate from one domain to another, without explicit input/output pairs. One of my favourite papers, Unsupervised Image-to-Image Translation Networks (code) uses this idea with generative adversarial networks (GANs). It works very well at e.g. transferring an image from a winter scene to a summer scene:
![]() Translating the winter scene on the left to a summer scene on the right. Example taken from https://www.youtube.com/watch?v=dqxqbvyOnMY&feature=youtu.be
Translating the winter scene on the left to a summer scene on the right. Example taken from https://www.youtube.com/watch?v=dqxqbvyOnMY&feature=youtu.be
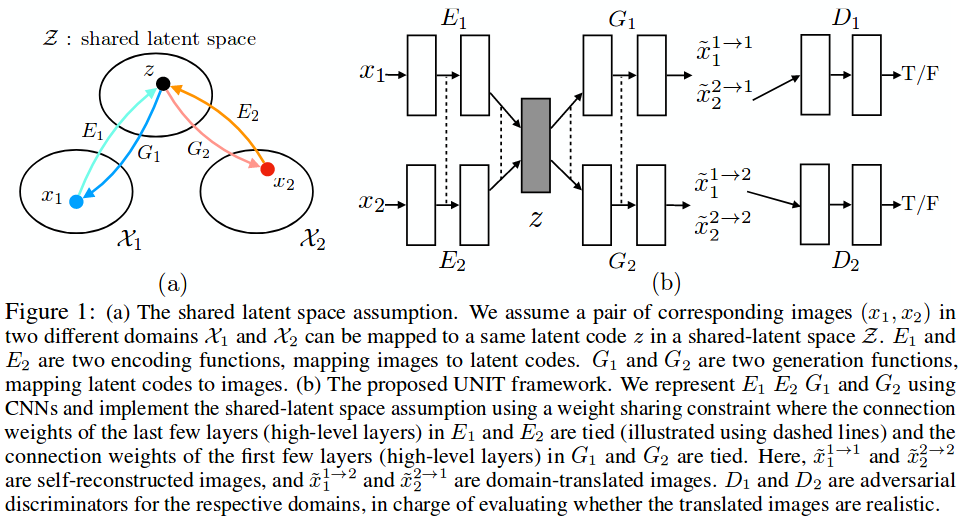 Details behind the key idea of Unsupervised Image-to-Image Translation Networks. Figure taken from the paper.
Details behind the key idea of Unsupervised Image-to-Image Translation Networks. Figure taken from the paper.
- Meta-Learning: where we are “learning-to-learn”.
- Graph Networks: investigating how to apply deep learning techniques to graph structures. The tutorial highlighted some interesting ideas, in particular that as data structures like graphs are very general. Thus, being able to take advantage of the benefits of deep learning models on such structures would open up many avenues of research.
- Program Induction: includes models that automatically learn how to write computer programs using example inputs/outputs.
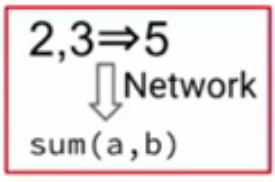 An example of program induction. Image taken from the tutorials slides.
An example of program induction. Image taken from the tutorials slides.
Best Paper Awards
- Safe and Nested Subgame Solving for Imperfect-Information Games (Paper, Video)
- A Linear-Time Kernel Goodness-of-Fit Test (Code, Paper, Poster)
- Variance-Bases Regularization with Convex Objectives (Paper)
Keynotes
I particularly enjoyed John Platt’s talk discussing how can we power the next 100 years. He argued that fusion will likely be the most important direction for allowing the world to use as much energy as a US resident does today, because energy is essential for a high standard of living. Given the wide variety of fusion research being undertaken, I found it particularly interesting to learn how they went about deciding which technique to focus their research and develop efforts. In particular, their investigation found that the approach the company TAE Technologies use could be most successfully integrated with machine learning techniques.
 Some of the key reasons why TAE’s approach to nuclear fusion was chosen — should integrate well with machine learning methods. Slide from Platt’s talk.
Some of the key reasons why TAE’s approach to nuclear fusion was chosen — should integrate well with machine learning methods. Slide from Platt’s talk.
Brendan Frey’s talk was on how machine learning is essential to help understand complicated and noisy biology. He also discussed how his company Deep Genomics is reducing the time it takes to develop drugs — I was fascinated about the idea of a cloud laboratory, which like cloud technologies for computing allows researchers use remote laboratories to conduct experiments for drug design/test by simply uploading a Python script.
Ali Rahmi’s talk (test-of-time award) discussed how machine learning has become the new alchemy. Instead he wants the “NeurIPS Rigour Police” to come back and help take machine learning from alchemy to electricity using “simple experiments and simple theorems [that] are the building blocks that help us understand complicated systems”. This was certainly one of the most talked about presentations at the entire conference.
Kate Crawford presented an important talk on the trouble with bias in machine learning systems. She highlighted how such biases can arise from many factors and thoughts about how to deal with it.
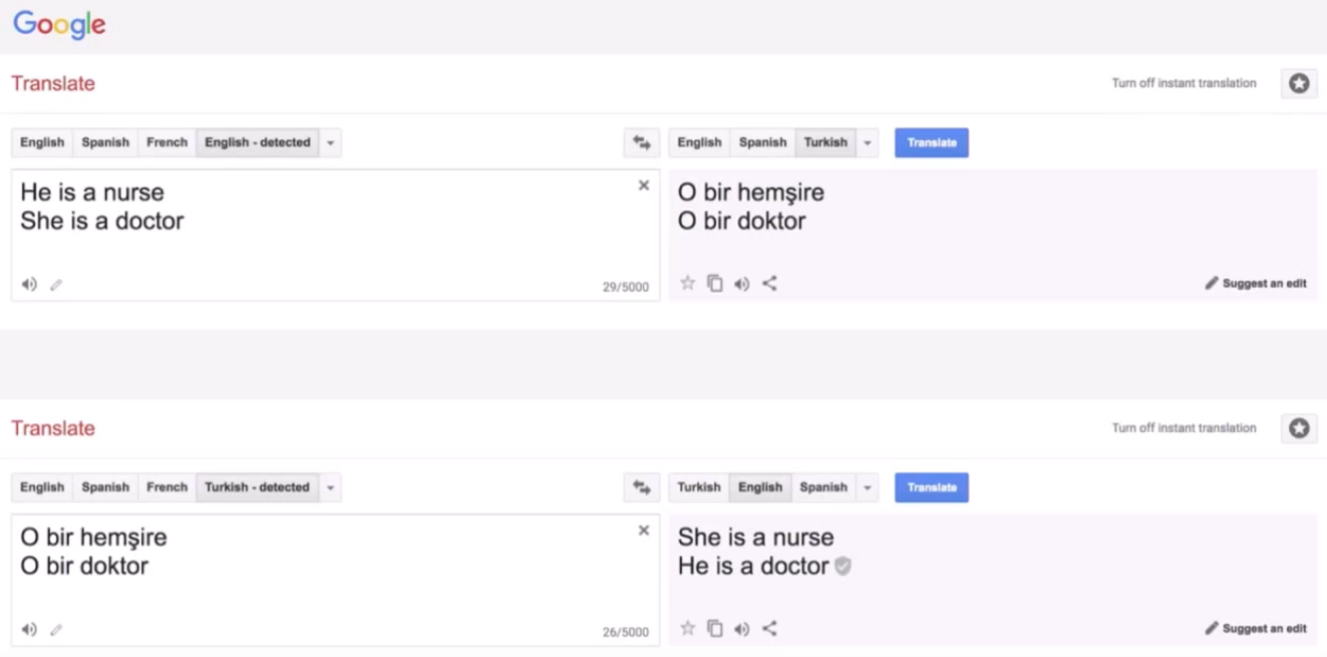 Example of bias in Google’s Translate system — “He is a nurse” -> [Turkish] -> “She is a nurse” (similar scenario seen when using the word “doctor”). Slide from Crawford’s talk.
Example of bias in Google’s Translate system — “He is a nurse” -> [Turkish] -> “She is a nurse” (similar scenario seen when using the word “doctor”). Slide from Crawford’s talk.
Lise Getoor presented on The Unreasonable Effectiveness of Structure. This introduced me to the concept of statistical relational learning (SRL) which combines principles from probability theory and statistics (to address uncertainty) with tools from knowledge representation and logic (to represent structure). She also discussed a GitHub tool, Probabilistic Soft Logic (PSL), for applying such methods.
Pieter Abeel presented a very interesting talk on Deep Learning for Robotics. After highlighting some of the successes deep reinforcement learning in particular has had, the bulk of his talk discussed the key problems that exist is robotics:
- Faster Reinforcement Learning: in particular, humans can often learn tasks much more quickly than the training required for existing DRL algorithms.
- Long Horizon Reasoning: the ability to reason and plan over a long time span.
- Taskability: the ability to tell robots what we want them to do. One such approach is to use imitation learning.
- Lifelong Learning: the ability to learn continuously (i.e. during deployment).
- Leverage Simulation: simulation is less expensive, dangerous, and is much faster/scalable to train that physical robots.
- Maximise Signal Extracted from Read World Experience: we what to ensure we are extracting as much real world signal from our (expensive) data collected from physical robots.
Yael Niv delivered a talk with a more neuroscience focus on Learning State Representations. She asked the question how do we learn from relatively little experience. I found some of the experiments conducted very fascinating.
Finally, Yee Whye Teh presented On Bayesian Deep Learning and Deep Bayesian Learning. Bayesian techniques was a big theme at NeurIPS, particularly methods for helping us to better reason about uncertainty and learn more efficiently from smaller datasets.
 Great slide from Yee Whye Teh keynote On Bayesian Deep Learning and Deep Bayesian Learning, comparing techniques from the two approaches.
Great slide from Yee Whye Teh keynote On Bayesian Deep Learning and Deep Bayesian Learning, comparing techniques from the two approaches.
Bayesian Deep Learning uses a Gaussian prior on the weights of a neural network.
Some of my favourite bits
Safe and Nested Subgame Solving for Imperfect-Information Games : This paper discusses the system called Libratus, the first AI to defeat top humans in heads-up no-limit Texas hold’em poker. Imperfect-information games are games where information is hidden from players (unlike games such as Go or Chess). This is important as there are many real-world decision-making situations that only have imperfect information. The accompanying video provides a helpful overview.
Dynamic Routing Between Capsules : One of the most anticipated paper published at this year’s NeurIPS was Geoff Hinton’s idea of “capsules” (lead authors for this particular paper were Sara Sabour and Nicholas Frosst). Capsule Networks try to address some of the short comings of Convolutional Neural Networks. Indeed a “discrimininatively trained, multi-layer capsule system achieves state-of-the-art performance on MNIST and is considerably better than a convolutional net at recognizing highly overlapping digits”. The paper also states “research on capsules is now at a similar stage to research on recurrent neural networks for speech recognition at the beginning of this century”. I found the accompanying video gives a great overview, and this blog post gives an excellent explanation behind the intuition and motivation behind them.
 Capsule Networks try to address some of the short comings of Convolutional Neural Networks. Indeed a “discrimininatively trained, multi-layer capsule system achieves state-of-the-art performance on MNIST and is considerably better than a convolutional net at recognizing highly overlapping digits”. Image from video.
Capsule Networks try to address some of the short comings of Convolutional Neural Networks. Indeed a “discrimininatively trained, multi-layer capsule system achieves state-of-the-art performance on MNIST and is considerably better than a convolutional net at recognizing highly overlapping digits”. Image from video.
Model Interpretability: understanding how your model makes predictions is as important as their accuracy. There were various papers attempting to approach this. One talk that I found particularly interesting was Streaming Weak Submodularity: Interpreting Neural Networks on the Fly. This paper introduces the STREAK algorithm, which not only identifies the parts of an image most important for explaining a prediction, but also does this much faster than previous algorithms.
 STREAK algorithm - not only identifies the parts of an image most important for explaining a prediction, but also does this fast. Slide from the talk.
STREAK algorithm - not only identifies the parts of an image most important for explaining a prediction, but also does this fast. Slide from the talk.
Another approach that aims to improve model interpretability was SHAP (SHapley Additive exPlanation), which unifies aspects of several previous approaches.
Deep reinforcement learning: David Silver provided yet another fascinating talk on their latest game-playing system. Announced only earlier in the week of the conference, Silver discussed the evolution from AlphaGo to AlphaZero, which learns entirely from self-play (plus the rules of a game). They made AlphaZero even more general, allowing it to master not only Go, but also Chess and Shogi (Japanese Chess).
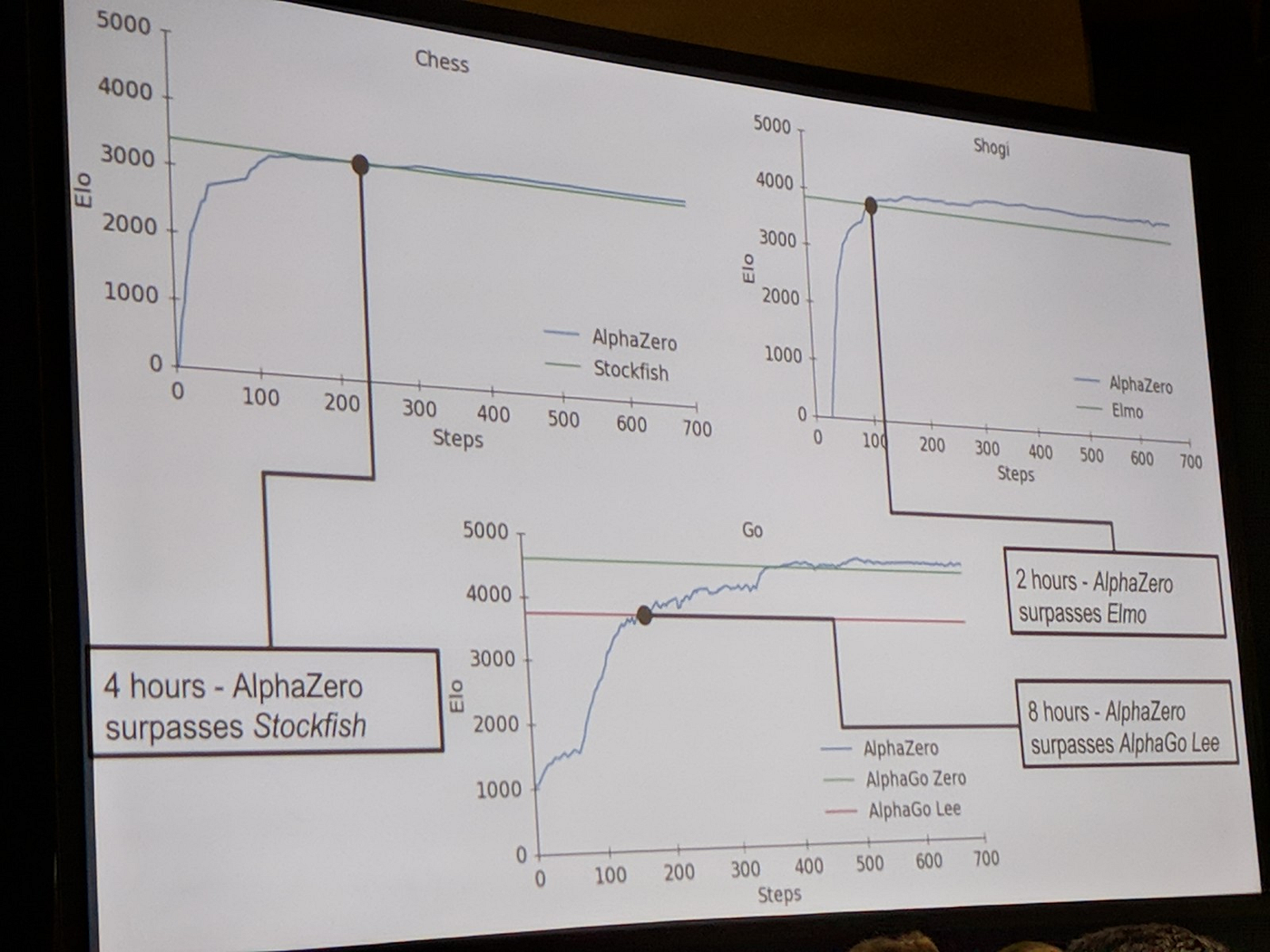 AlphaZero surpassed all previous masters (fast!)
AlphaZero surpassed all previous masters (fast!)
 Unlike StockFish, the leading chess game engine which uses many hand-crafted game plays, AlphaZero learns in a much more general way primarily driven through self-play — interestingly AlphaZero did learn some of the well-know moves in the slide above during training.
Unlike StockFish, the leading chess game engine which uses many hand-crafted game plays, AlphaZero learns in a much more general way primarily driven through self-play — interestingly AlphaZero did learn some of the well-know moves in the slide above during training.
Another aspect I found fascinating with AlphaZero was how it also learned completely new game play that have not be discovered previously. This included weird behaviour where AlphaZero may e.g. sacrifice a Queen, only for it to be seen (many moves later) why it took such an action.
 In his talk Ilya Sutskever hypothesised that self-play will be a key aspect to AGI.
In his talk Ilya Sutskever hypothesised that self-play will be a key aspect to AGI.
Other code implementations I’m interested in trying:
- A Bayesian Data Augmentation Approach to Learning Deep Models (Keras)
- Mean teachers are better role models (PyTorch and TensorFlow) — a state-of-the-art semi-supervised method for image recognition.
- ELF: An Extensive, Lightweight and Flexible Research Platform for Real-time Strategy Games
- Sharkzor: Interactive Deep Learning for Image Triage, Sort and Summary — although not currently available (the author mentioned they intend to open source this soon), this demonstrated a fantastic web application for machine-learning assisted image classification. I’m very much looking forward to playing with this tool. I also believe it will provide a great platform for non-technical people to perform image classification.
Miscellaneous
- A very comprehensive set of notes for NeurIPS 2017.
- Here is an interesting visualisation of the 737 Twitter accounts most followed by members of the NeurIPS2017 community.
- https://www.matrixcalculus.org/ — enables you to compute matrix derivatives using symbolic differentiation.
You know AI is a bubble when Intel invites Flo Rida to perform at their NeurIPS party pic.twitter.com/Psyqlt8vcl
— hardmaru (@hardmaru) December 3, 2017
Other cool results I came across but not necessarily presented at NeurIPS
- Don’t decay the learning rate, increase the batch size — results show that you should see the same learning curve.
- Distilling a Neural Network Into a Soft Decision Tree — using a trained deep neural network to create a type of soft decision tree, helping to explain why it makes a particular classification decision on a particular test case.
- Michael Nielsen’s video providing intuition behind the universal approximation theorem for neural networks.
Any thoughts/corrections welcome!